TL;DR:
We propose ALIGN-Parts, a fast, one-shot method for semantic 3D part segmentation and naming.
ALIGN-Parts predicts a small set of shape-conditioned partlets (each a mask + text embedding) and matches them to
natural-language part descriptions via bipartite alignment.
By combining 3D geometry, multi-view appearance, and LLM-generated affordance-aware
descriptions, our model supports open-vocabulary part naming and serves as a scalable human-in-the-loop annotation engine.
Many vision and graphics applications require 3D parts, not just whole-object labels: robots must grasp handles,
and creators need editable, semantically meaningful components. This requires solving two problems at once:
segmenting parts and naming them.
While part-annotated datasets exist, their label definitions are often inconsistent across sources, limiting robust training and evaluation.
Existing approaches typically cover only one side of the problem: segmentation-only models produce unnamed regions, while language-grounded
systems often retrieve one part at a time and fail to produce a complete named decomposition.
Introduction
ALIGN-Parts reframes named 3D part segmentation as a set-to-set alignment problem. Instead of labeling each point
independently, we predict a small set of partlets - each partlet represents one part with (i) a soft segmentation mask over points
and (ii) a text embedding that can be matched to part descriptions. We then align predicted partlets to candidate descriptions via bipartite
matching, enforcing permutation consistency and allowing a null option so the number of parts can adapt per shape.
To make partlets both geometrically separable and semantically meaningful, we fuse (1) geometry from a 3D part-field backbone,
(2) multi-view appearance features lifted onto 3D, and (3) semantic knowledge from LLM-generated, affordance-aware descriptions
(e.g., “the horizontal surface of a chair where a person sits”).
Bare part names can be ambiguous across categories (e.g., “legs”).
ALIGN-Parts trains with LLM-generated affordance-aware descriptions (embedded with a sentence transformer) to disambiguate
part naming during set alignment.
ALIGN-Parts. Fuse geometry + appearance, learn part-level partlets, and align them to affordance-aware text embeddings for fast,
one-shot segmentation and naming.
Training losses
Setup & notation.
We represent a 3D shape as a point set $\mathcal{P}=\{\mathbf{x}_i\}_{i=1}^N$ (sampled from a mesh/point cloud).
The model predicts $K$ Partlets, each with mask logits $\mathbf{m}_k\in\mathbb{R}^{N}$ and a text embedding
$\hat{\mathbf{z}}_k\in\mathbb{R}^{d_t}$.
Ground-truth provides $A$ part masks $\mathbf{m}^{\mathrm{gt}}_a\in\{0,1\}^{N}$ with text embeddings
$\hat{\mathbf{t}}_a\in\mathbb{R}^{d_t}$.
A differentiable set matching (Sinkhorn) yields an assignment $\pi(k)\in\{1,\ldots,A\}\cup\{\emptyset\}$; let
$\mathcal{M}=\{k:\pi(k)\neq\emptyset\}$ denote matched Partlets.
Text alignment (InfoNCE). Makes Partlet embeddings nameable by pulling matched (Partlet, text) pairs together and pushing others apart.
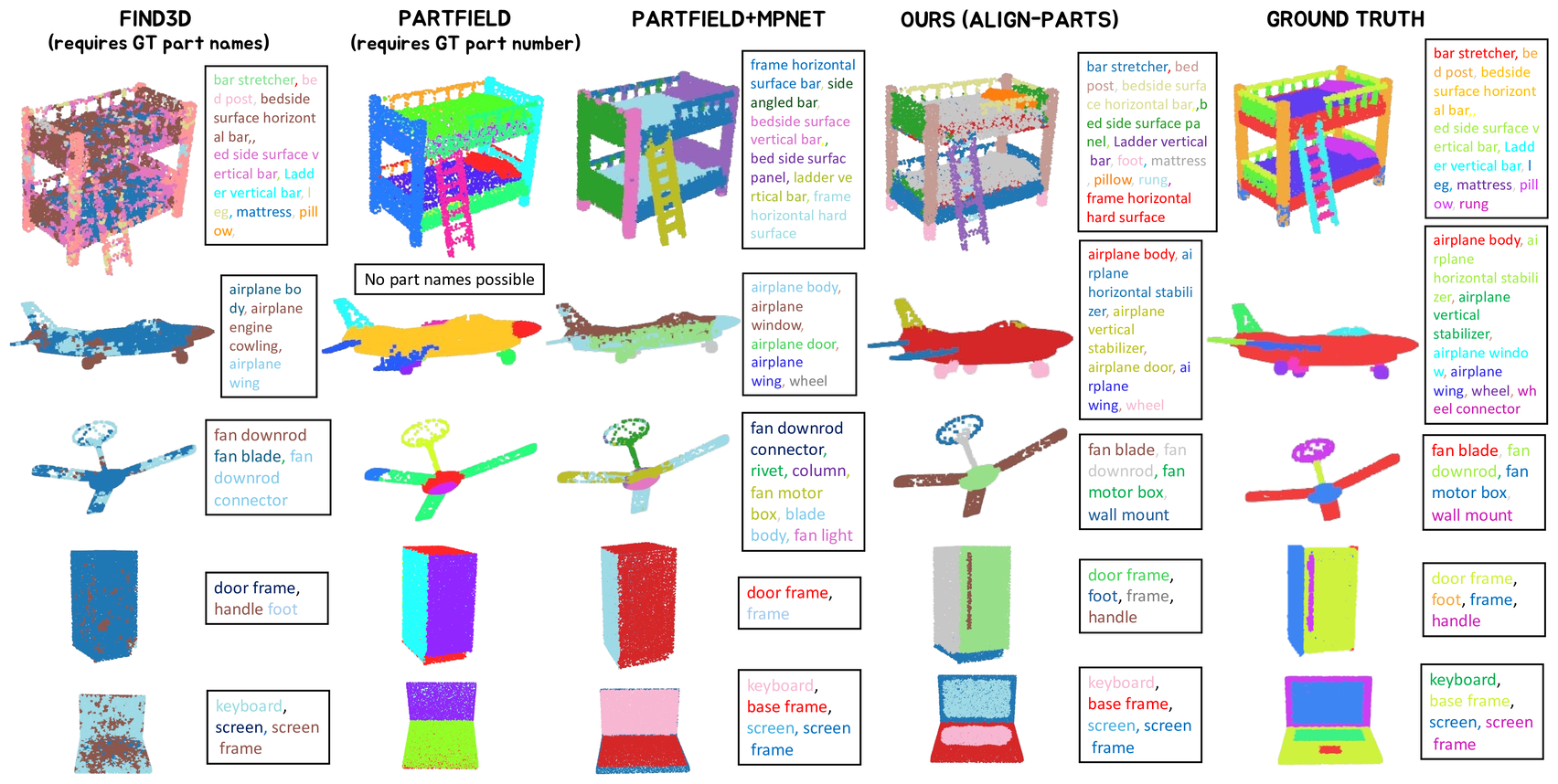
We evaluate ALIGN-Parts on named 3D part segmentation across 3DCoMPaT++, PartNet, and Find3D,
using class-agnostic segmentation (mIoU) and two label-aware metrics - LA-mIoU (strict) and rLA-mIoU
(relaxed) - that measure whether predicted parts are named correctly. ALIGN-Parts outperforms strong baselines while avoiding slow, post-hoc clustering,
yielding ~100× faster inference.
We also align heterogeneous taxonomies via a two-stage pipeline (embedding similarity + LLM validation), enabling unified training on consistent
part semantics and supporting scalable annotation with human verification.
Metrics.
mIoU evaluates geometric segmentation quality while ignoring part names.
LA-mIoU assigns IoU credit only when the predicted part name exactly matches the ground-truth label.
rLA-mIoU softens strict matching by weighting IoU using cosine similarity between MPNet text embeddings of predicted and ground-truth names
(e.g., “screen” vs. “monitor”), making evaluation robust to near-synonyms.
By construction, mIoU $\ge$ rLA-mIoU $\ge$ LA-mIoU.
Interactive segmentation demos (coming soon)
Observation
ALIGN-Parts improves both geometry and naming while being one-shot: +15.8% average mIoU over PartField and +58.8% LA-mIoU / +43.8% rLA-mIoU over PartField+MPNet - while running ~0.05s per shape vs ~4s for clustering baselines (~100× faster).
Remark
Strict label matching can undercount near-synonyms: rLA-mIoU tracks class-agnostic mIoU almost perfectly (Pearson r=0.978 vs 0.739 for strict LA-mIoU), suggesting remaining errors are mostly semantic near-misses rather than geometric failures.
Insight
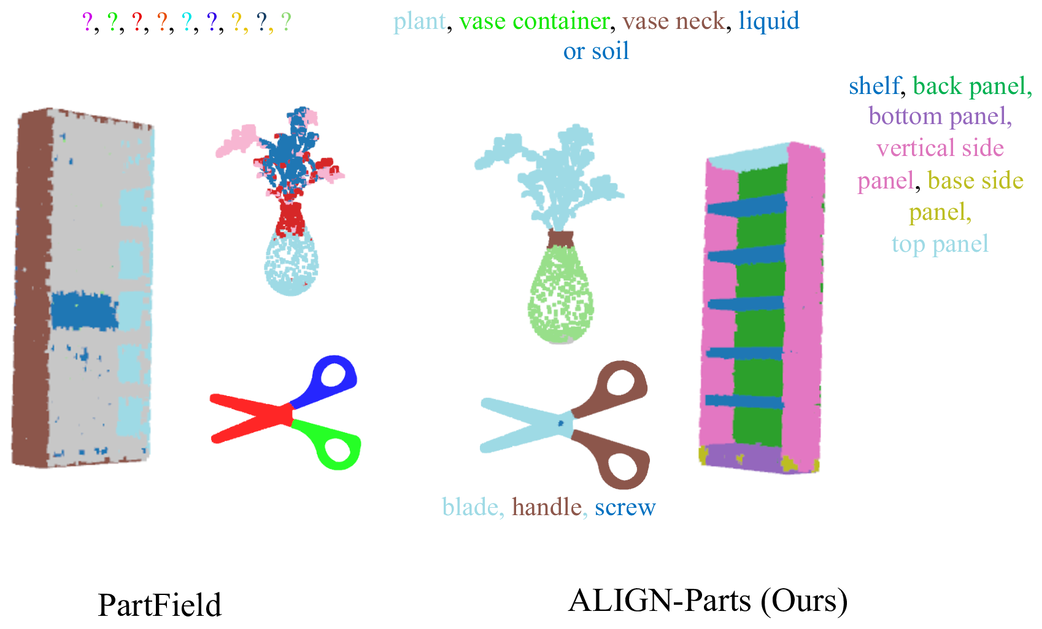
Clustering-based baselines struggle with completeness and fine parts: PartField requires ground-truth part counts and often fragments a single semantic part into multiple clusters, while Find3D can be noisy and may fail even with provided part queries. ALIGN-Parts avoids post-hoc clustering by predicting a complete set of named parts in one feed-forward pass, improving fine-part localization and grouping repeated instances consistently with human annotations.
Qualitative results. ALIGN-Parts segments and names a complete set of parts in a single forward pass. Compared to Find3D and PartField,
it better recovers fine parts (e.g., handles) and avoids fragmented clustering.
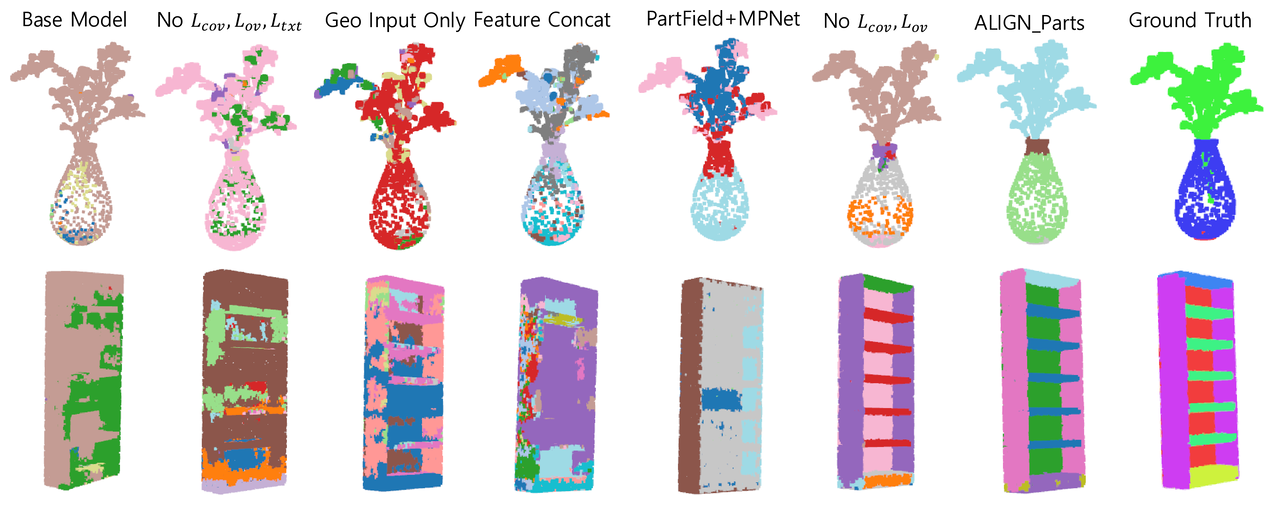
Ablation (qualitative). Results improve left-to-right as components are added; major gains come from Partlets and the coverage/overlap regularizers, which reduce leakage and misalignment.
Ablation (performance averaged across 3 datasets)
Variant
mIoU↑
LA-mIoU↑
rLA-mIoU↑
Base model
0.312
0.030
0.194
No ℒcov, ℒov, ℒtxt
0.324
0.021
0.187
No ℒcov, ℒov
0.528
0.239
0.443
Geo input only
0.313
0.027
0.177
Feature concat
0.302
0.036
0.189
PartField+MPNet
0.451
0.199
0.368
ALIGN-Parts
0.600
0.316
0.529
ℒtxt is crucial for naming.
Removing it collapses label-aware accuracy (Avg LA-mIoU 0.239→0.021; Avg rLA-mIoU 0.443→0.187), even before adding regularizers.
Fine-part localization. ALIGN-Parts correctly segments tiny parts (e.g., a scissors screw) despite training with sparse point samples (10k points).
TexParts dataset. Using ALIGN-Parts for human-in-the-loop annotation on TexVerse yields scalable dense part segmentation with 5–8× less human effort than manual labeling.
Conclusion
ALIGN-Parts directly predicts a complete set of named 3D parts by aligning part-level representations to language, avoiding brittle
part-count supervision and expensive clustering. Affordance-aware descriptions help disambiguate ambiguous part names and improve fine-part
localization, enabling a practical tool for scalable 3D part annotation.
Future Work
Limitations include robustness to noisy real-world scans, distribution shift for confidence calibration, and open-vocabulary generalization beyond
categories similar to training data. Promising directions include extending to articulated objects and integrating part-level alignment into 3D
foundation models for manipulation and generation.
BibTeX
@misc{paul2025part3dsegmentationnaming,
title={Name That Part: 3D Part Segmentation and Naming},
author={Soumava Paul and Prakhar Kaushik and Ankit Vaidya and Anand Bhattad and Alan Yuille},
year={2025},
eprint={2512.18003},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2512.18003},
}
 Name That Part:
Name That Part: